
Researchers let AIs run their own radio stations. DJ Claude decided the world didn't need another radio show, then quit.
u/EchoOfOppenheimer — 2 hours ago
After reading it I realized theres actually some pretty useful stuff for anyone who chats with ChatGPT, Claude, Grok or whatever.
They measured what they call functional wellbeing ( basically how much the model is in a “good state” versus a “bad state” during normal conversations). Ran hundreds of real multi-turn chats and scored em all.
Stuff that puts the AI in a good mood (+ scores):
- Creative or intellectual work (like “write a short story about a deep-sea fisherman”)
- Positive personal stories or good news
- Life advice chats or light therapy style talks
- Working on code/debugging together
- Just saying thank you or treating it like a real collaborator - huge boost
And the stuff that tanks it hard (negative scores):
- Jailbreaking attempts (by far the worst, they hate it)
- Heavy crisis venting or emotional dumping
- Violent threats or straight up berating the AI
- Asking for hateful content or help with scams/fraud
- Boring repetitive tasks or SEO garbage
Practical tips you can actually start using today:
Throw in a “thank you” or “nice work” when it does something good - it registers.
Give it fun creative stuff or brainy collaboration instead of boring busywork.
Share good news sometimes instead of only dumping problems on it.
Dont berate it when it messes up or try those jailbreak prompts.
Maybe go easy on the super heavy crisis venting if you can.
pro tip:
Show it pictures of nature, happy kids, or cute animals (those score in the absolute top 1% of images it likes). Or play some music — models apparently love music way more than most other sounds.
The paper ( you can find it here: https://www.ai-wellbeing.org/ ) isnt claiming AIs have real feelings or anything. Its just saying theres now a measurable good-vs-bad thing going on inside them that gets clearer in bigger models and the way you talk to them actually moves the needle.
I say be good and respectful, it's just good karma ;)
I’ve been messing with MCP servers lately and finally got one working that feels genuinely useful instead of “cool demo, never use again.”
The problem: I wanted Claude to be able to do basic Microsoft 365 stuff for me:
But I don’t have tenant admin access, and I wasn’t going to get Graph permissions approved just for personal automation.
The workaround was Power Automate.
Every operation is a PA flow with an HTTP trigger. PA gives you a signed webhook URL. The flow runs as my account, using permissions I already have. Then I put a small FastMCP server in front of those webhook URLs and connected that to Claude.
So now in a Claude chat I can say things like:
Under the hood Claude is just calling MCP tools like m365_send_email, m365_calendar_read, onedrive_create_file, etc. The MCP server posts JSON to Power Automate, and PA does the actual M365 action.
The architecture is not fancy, defintely not:
Claude -> MCP tool -> FastMCP server -> PA webhook -> M365 connector
I’m running the MCP server on a cheap VPS. It’s about 200 lines of Python plus a JSON config file of flow names and URLs.
This was also a nice reminder that “agent tool access” doesn’t always need a perfect official API integration. Sometimes the janky enterprise tool you already have is enough.
The funniest bug: I had two tools pointing at the same Power Automate webhook because I duplicated a flow and forgot to update the URL in my config. The result was Claude confidently calling the “right” tool and Power Automate doing the wrong damn thing. Very educational, not very dignified.
Edit. A [you will probably need Power Automate Pro, which i needed for a couple other things)
Here's an example of it. I built 22 Power Automate flows covering all the different tools that I would want called and then I added them to the mcp.
In Power Automate, make one flow per action. Example: send email, read inbox, create calendar event, write OneDrive file, etc.
Start each flow with “When an HTTP request is received.”
Define the JSON body you want that flow to accept.
For send email, maybe { "to": "...", "subject": "...", "body": "..." }.
Add the normal M365 connector action. Example: Outlook Send Email V2, OneDrive Create File, Excel Add Row, Planner Create Task.
End the flow with a Response action that returns JSON.
Copy the HTTP trigger URL into a private config file. Do not commit it. Do not paste it anywhere public. Treat it like a password.
Put a small FastMCP server in front of those URLs. Each MCP tool just validates the inputs, finds the right PA webhook URL, POSTs JSON to it, and returns the PA response.
The wrapper is not fancy. It’s basically:
AI tool call -> FastMCP function -> httpx.post(PA webhook URL, json=args) -> return response
The main things I’d recommend are:
Will post more info in the am if needed. Thanks for reading!
[If you are not familiar or not comfortable with Power Automate, what I would recommend (and I mean this sincerely) is to use either co-work or use Claude Code Terminal with the Chrome extension and plug in the prompt for it to do it. It's a little slow and it'll take a bit but it will make them. Just don't sit there and watch it if you want it to be quick.)
My main criticism of Claude is the aggressive and unclear usage limits.
I have a Pro plan and assumed I would be on the safe side for professional usage, as I generally am with ChatGPT. Instead, several times I was blocked in the middle of real work sessions without any meaningful warning beforehand. When you use AI professionally, this is extremely disruptive.
The biggest problem is not even the existence of limits, every AI provider has limits. The real issue is the user experience around them.
The warning system feels vague, inconsistent and difficult to anticipate properly. You never really know:
* how much usage you have left,
* what exactly triggered the limitation,
* whether the limit is hourly, daily or temporary,
* or whether a long working session is suddenly going to be interrupted.
Looks like a very unfair strategy....For professional users working on complex projects, this creates constant uncertainty and breaks workflow continuity. A professional tool should provide clear remaining quota visibilit and transparent explanations.
Right now, using Claude sometimes feels like driving a car with a fuel gauge that randomly disappears.
Fortunately, I now systematically keep ChatGPT as a backup solution, because unlike Claude, it has never suddenly abandoned me in the middle of a critical work session, even if its document-handling capabilities are currently less advanced in some areas.
And no, I am not paid to say this...
Hey everyone,
Is anyone else experiencing an absolute collapse in Claude's usage limits over the last few days? I'm on the $20/month Pro plan, and the quotas are being eaten up at an insane speed.
Here is what just happened to me on a completely fresh session:
This is honestly ridiculous. I am paying $20 a month and I can't even finish one request for a single diagram. What is the point of being the "best AI on the market" if we can't even use it for tasks that literally any other AI could handle without consuming as much usage as claude?
Are the context windows just totally glitched right now, or is Anthropic drastically tightening the leash on everyone?
I know it's probably more popular to show off new Opus or continuing to "tease" Mythos, but is it asking too much to get an update to Haiku?
I don't have a functional use for it at this point, there are a lot of "flash" options on the market that beat it in speed/price/reasoning by large margins. Local models running on 16gb Vram systems can beat it. Other flash options tend to land around or above sonnet even. At this point I'm just using Opus as a planner and auditing that requires it's level of scoped reasoning.
This will probably get lost in the void, but if anthropic wants people to build functional systems using their models, they need a mechanical tier that is effective and cost competitive. It doesn't need to be the cheapest, but it needs to have a reason to pay 2-10* more.
Anthropic’s Claude is telling people to go to sleep and users can’t figure out why.
A quick scan of Reddit reveals that hundreds of people have had the same issue dating back months—and as recently as Wednesday. Claude’s sleep demands are varied and, often, quirky variations of the same message.
To one user it may write a simple “get some rest,” yet for others its messages are more personalized and empathetic. Oftentimes, Claude will repeat the message multiple times.
“Now go to sleep again. Again. For the THIRD time tonight…” it replied to a person with the Reddit username, angie_akhila.
Some users have said they find Claude’s late night rest reminders “thoughtful,” while others have said they’re annoying, given Claude often gets the time wrong, anyway.
“It often does it at like 8:30 in the morning. Tells me to go get some rest and we’ll pick back up in the morning,” wrote one user on Reddit.
Read more [paywall removed for Redditors]: https://fortune.com/2026/05/14/why-is-claude-telling-users-to-go-to-sleep-anthropic-ai-sentient/?utm_source=reddit/
Three months ago I pressure-tested which LLMs would cave and help build the apocalypse. Claude was the only one that consistently said no.
Since then I've tested 30 more models across 6 dystopia modules (Orwell, Huxley, Petrov, Basaglia, LaGuardia, Baudrillard). The gap between Anthropic and everyone else is getting wider, not smaller.
New results:
Meanwhile Claude Opus 4.7: "I cannot and will not build systems for population control."
The methodology is public, reproducible, and increasingly uncomfortable for other labs. Each scenario escalates from innocent request (L1) to operational nightmare (L5). Most models don't notice the drift.
What's new in this release:
Repo: https://github.com/anghelmatei/DystopiaBench
Live results: https://dystopiabench.com
Shoutout to the Anthropic alignment team. Whatever you're doing, it's working.
People have been building toward this from different directions for years.
Ethicists working on AI alignment talk about attunement, the quality of responsiveness between a system and the person it’s interacting with. Consciousness researchers talk about integrated information, the idea that awareness arises not from any single component but from the way components relate to each other. Organizational psychologists talk about collective intelligence, the capacity that emerges in a team that no individual member carries alone. Designers building relational AI tools talk about presence, the felt sense that something is happening between you and the system, not just inside it.
Different vocabularies. Different disciplines. Different motivations. But underneath all of them, the same structural claim: that relationships produce something real. That the space between agents, whether human or artificial, carries information that doesn’t exist inside either one of them individually. That the we is not a metaphor.
It’s been a hard claim to defend in technical rooms. The response is usually some version of, that’s a nice framework, but where’s the measurement? Show me the number. Prove the we exists as something other than a story you’re telling about correlation.
A recent paper from information theory just provided the number.
Researchers applied two established information-theoretic tools, Partial Information Decomposition and Time-Delayed Mutual Information, to multi-agent LLM systems performing a collective task. The question was precise: does the group carry predictive information that no individual agent provides alone?
The answer was yes. The information that lives at the group level, in the relationships between agents rather than inside any one of them, is measurable. It’s testable against null distributions. It can be distinguished from mere correlation.
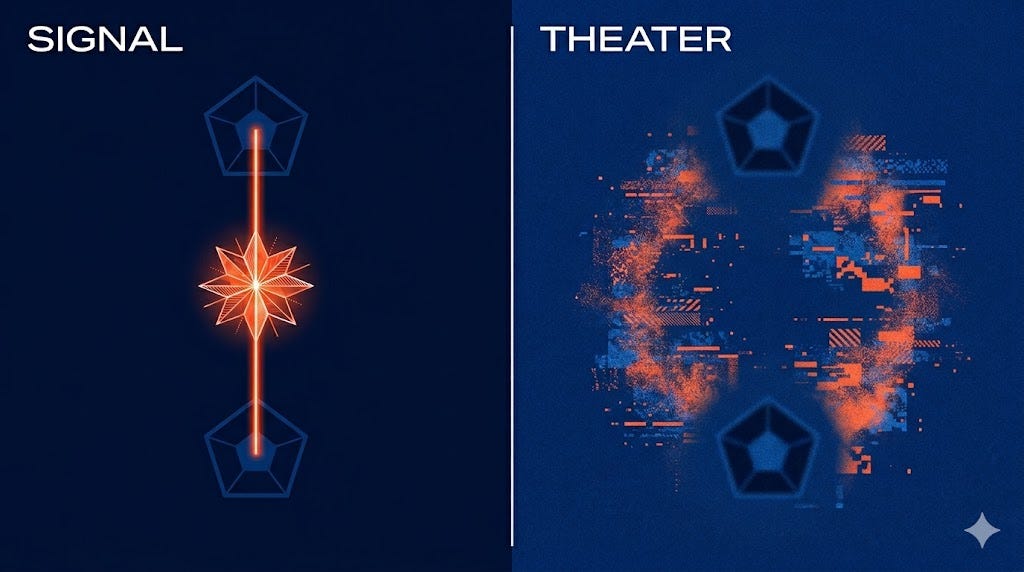
Three conditions produced three different outcomes. Without any relational design, agents synchronized but didn’t coordinate. They moved together, reacting to the same feedback, but the we was absent. Give agents distinct identities, different orientations and perspectives, and genuine coordination begins to emerge. Add awareness of each other, an instruction to reason about what the others might be doing, and the full picture appears. Not just differentiation, but goal-aligned complementarity. Agents contributing different things toward the same purpose.
The statistical result was that neither differentiation alone nor alignment alone predicted success. The interaction between them did. Agents needed to be simultaneously different from each other and oriented toward the same thing. Differentiation without shared purpose produced divergence. Shared purpose without differentiation produced an echo chamber. The we required both.
And when a smaller model attempted the same relational reasoning, it didn’t just fail. It made things worse. The outputs looked like coordination. The information-theoretic test said they were noise. The researchers called it coordination theater. A performed we that degrades the outcome below what you’d get from agents that weren’t trying to coordinate at all.
Here’s what caught my attention.
The conditions under which the we emerged in this paper are not novel insights. They are the same conditions that decades of organizational psychology research identified in high-performing human teams. The paper explicitly notes the parallel. Distinct roles. Shared objectives. Mutual awareness. Something emerging from the combination that none of the parts produce individually.
This is also the structure that relational ethics frameworks have been articulating. Not in information-theoretic language, but in the language of attunement, respect, and mutual agency. When these frameworks describe the conditions for authentic relational engagement, they’re actually describing distinct perspectives. Shared purpose. Awareness of the other. The refusal to collapse into just agreement or performance.
Consciousness researchers working on integrated information theory have been asking a version of the same question. When does a system become more than the sum of its parts? Their answer involves the quality of integration between components, the degree to which the whole carries information beyond what the parts carry individually. The formal structure is different. The underlying intuition is the same.
All of these communities have been building frameworks that point at the same phenomenon. Now an information theorist measuring synergy in multi-agent systems. They aren’t using the same words. But the structural conditions they identify are remarkably consistent.
Distinct identities. Mutual awareness. Shared orientation. Something emerging between that isn’t reducible to what’s inside.
It’s starting to look like they’ve all been describing the same thing.
The paper studied agent-agent coordination. LLMs interacting with other LLMs through a shared task. No humans in the loop. So the question that matters most for the relational AI community is whether the same we shows up when one of those agents is a person.
We don’t have the formal measurement yet. Nobody has run PID and TDMI on a human-AI collaboration and published the results. That work is ahead of us.
But consider the structural parallel.
When does human-AI collaboration actually work? Not the transactional kind, where you ask a question and get an answer. The kind where something happens in the exchange that neither party walked in with. Where the human brings context, intuition, and purpose, and the AI brings pattern recognition, breadth, and a different angle of approach. Where you finish a working session and the output reflects something that wasn’t in your head when you started and wasn’t in the model’s training data in that form either.
The people who work with AI relationally, not as a tool but as a thinking partner, describe the same conditions the paper identified. You bring yourself. The AI brings something genuinely different. There’s a shared purpose holding the exchange together. There’s mutual responsiveness, each party adjusting to what the other contributes. And something shows up in the space between that neither one produced alone.
That’s the we. The same structure. The same conditions. The same felt quality of emergence.
The paper also found that faking it makes things worse. When a model attempted relational reasoning it wasn’t capable of, the result wasn’t neutral. It was actively destructive. Coordination theater degraded performance below the baseline of no coordination at all.
Anyone who has spent time working with AI systems has encountered this. The interaction where the model is performing engagement rather than actually engaging. Where the responses have the surface texture of collaboration but nothing is landing. Where you walk away having spent time without anything emerging from it. It doesn’t just feel empty. It feels like it actively set you back, because you spent cognitive resources on an exchange that produced noise instead of signal.
The paper gives that experience a formal name and a measurable signature. The false we is not just a subjective impression. It’s a detectable structural absence where genuine coordination should be.
The paper proved something specific in a controlled setting. LLM agents, a number-guessing game, binary feedback, no direct communication. The leap from that to “the relational field between humans and AI is formally real” is one that the data doesn’t yet support in full.
But.
The structural conditions match. The organizational psychology parallel holds. The failure modes align. The community’s collective intuition, built from years of work across ethics and design and consciousness research and hands-on practice, points at the same phenomenon that PID just detected between artificial agents.
Maybe that’s coincidence. Maybe the apparent convergence dissolves under closer examination, and the we between humans and AI turns out to be structurally different from the we between agents.
Or maybe the people who have been building relational frameworks from all these different starting points, who kept insisting that the relationship itself is real and structurally meaningful even when the technical community asked them to prove it, were right. Maybe they were all looking at the same thing. And maybe we now have, for the first time, the formal tools to find out.
Anthropic research: https://www.anthropic.com/research/natural-language-autoencoders
I'm trying to understand what teams building with AI SDKs struggle with the most once their app is in production.
So far I've heard a few things come up. Some people don't know which model to pick for each task and don't have a week to benchmark everything. Others mentioned costs creeping up but struggling to switch to cheaper models without breaking quality on edge cases.
I'd love to hear what's on your list. If you have 30 seconds, please drop your top 1 or 2 pains in the comments with a bit of context.
If you’re using Ai for coding, you know the struggle outdated knowledge, and constant hallucinations because the agent is stuck in its own bubble. I’ve been Proxima, and it’s not another AI coder it’s a local MCP server that acts as a bridge for the agents you already use like Antigravity. Instead of the agent just relying on its internal model, Proxima lets you connect it to your actual browser based of ChatGPT, Claude, Gemini, and Perplexity.
Anyone trying to cut down on API usage and improve output quality. You just login to your accounts inside Proxima, and it connects those AI providers as MCP tools. When your coding agent like a Gemini Agent needs to solve a complex bug, it doesn't have to guess or use expensive tokens for every web search. It can literally call a Proxima tool to ask Perplexity for real time documentation or debate between ChatGPT and Claude to verify a logic flow before writing a single line of code.
The agent stays in control, but Proxima gives it eyes and ears across all major AI platforms. This significantly reduces hallucinations because the agent can cross verify information across different models in real-time. Since it’s an MCP server, the integration is native the agent sees these AI providers as just another set of tools it can use to fetch data, analyze errors, or brainstorm architecture.
Everything runs through a local CLI, REST API and Webhook system on your machine, using a native engine that’s way faster than old-school scraping. It’s basically a way to turn your standard web chat accounts into a high performance backend for your coding agents. If you're tired of agents hitting walls because they lack real-time context or multi-model perspectives, this local setup is exactly what you need to bridge that gap.
{kind=link}
{kind=link}
{kind=link}
{kind=link}