
Could an AI 1000x smarter than us manipulate us?
u/KeanuRave100 — 3 hours ago
Do you guys feel exhausted when you write with a pen for essays, which pen is recommended? What would you prefer, speed or comfortability? I am looking for a pen that can do that to write better
hysics-Informed Neural Networks are interesting because they break the standard ML paradigm: instead of approximating an unknown function from data alone, they exploit a known PDE constraint that the solution must satisfy. In principle this should make them converge faster and generalize better.
In practice the loss function makes them notoriously hard to train. The loss is a weighted sum of multiple terms (PDE residual, boundary conditions, initial conditions, data), each with different scales and gradient magnitudes. Several papers have characterized what goes wrong:
Wang, Teng & Perdikaris (2021) showed empirically and theoretically that during training, the gradients from different loss components become severely imbalanced. The optimizer follows whichever loss has the loudest gradient, regardless of which one matters most.
Wang, Yu & Perdikaris (2022) used Neural Tangent Kernel theory to show that the PDE residual term has much smaller eigenvalues than the boundary loss. The network learns boundaries quickly and interior physics slowly — often it never catches up.
Krishnapriyan et al. (NeurIPS 2021) demonstrated that even on simple PDEs like the convection equation, PINNs systematically fail to converge as the convection coefficient grows. This is on textbook problems with reasonable hyperparameters.
Mitigations exist (adaptive loss weighting, causal training, curriculum approaches, architectural fixes that hard-code boundary conditions) but none has fully solved the problem.
I wrote a longer version with full references and applications here: https://cristobalsantana.substack.com/p/the-pinn-loss-function-where-physics
Curious if anyone here has dealt with these training pathologies in production and what worked for you.
i have a rx 580, and i wanna know if i can run YOLO model for my object detection on my rx 580?
Been going down a mechanistic interpretability rabbit hole for the past few weeks and ended up building this thing called AXON.
The idea: every time GPT-2 generates a token, its residual stream gets passed through a Sparse Autoencoder (Joseph Bloom's pretrained SAE). The SAE decomposes it into human-interpretable feature: hings like "European geography", "capital cities", "French language" and streams those to the browser over WebSocket, where they show up as a live 3D force graph.
Nodes = SAE features. Edges = features that fired together on the same token. Node brightness = activation strength. The whole graph evolves token by token.
What surprised me most: type "The capital of France is" and you can literally watch geography features, proper noun features, and completion-pattern features light up before the word "Paris" even gets generated. It's not what the model outputs that's interesting it's what's happening right before it decides.
Stack: TransformerLens + SAELens on the backend, FastAPI WebSocket for streaming, Three.js + 3d-force-graph on the frontend. Runs on CPU (~800ms/token) or GPU (~35ms on a 4050). Labels come from Neuronpedia's API and get cached locally.
You can also swap in other models — GPT-2 medium/large/xl, Pythia variants, Gemma-2-2B — as long as there's a pretrained SAE for it in SAELens.
GitHub: https://github.com/09Catho/axon
Would love feedback and stars especially from anyone who's worked with SAEs before curious whether the co-activation edges are actually meaningful or just noise at this layer.
Hey r/DeepSeek,
Who says we need an H100 cluster or the latest expensive GPUs to run frontier MoE models? I wanted to see how far we could push a single node of consumer legacy hardware, so we spent less than $2,500 total to build a budget machine that successfully runs DeepSeek-V4-Flash (284B total, 13B active) locally!
Surprisingly, we managed to hit around 255 prefill tokens/s with a very tight memory budget.
Here is a quick breakdown of how we achieved this "legacy donkey pulling a massive MoE chariot" feat via hardware-software co-optimization:
The entire implementation, deployment script, and preliminary tech report are 100% open-sourced. I'd love to hear your thoughts, benchmarks, or feedback from fellow system/compiler hackers here!
🔗 GitHub Repository:https://github.com/lvyufeng/deepseek-v4-2080ti
(Note: I submitted the detailed report to arXiv a few days ago, but it’s currently caught in the manual moderation queue—likely because a rookie author throwing a 2080 Ti at DeepSeek-V4 triggered their review boundaries lol. Will update with the arXiv link once it's cleared!)
I’m interested in learning more about the historical development and fundamental concepts of ML/DL/LLMs but I’m finding that everything I come across is either too dumbed down or too advanced (by advanced I mean skipping right to the current edge of development). I am not a computer scientist or developer but I got my first computer in the mid 80s, have always dabbled in hobby coding, did well in stats ii and calc iii and have held a variety of STEM jobs that require mathematical understanding, so I may not be passing assessments on proofs or anything but I feel like I can read and understand mathematical and logical principles fairly well. I’m
Fascinated by learning more about how we got from primitive text prediction to where we are today for both intellectual and practical purposes. Can anyone recommend any , either print or online, that would help me gain knowledge in this area?
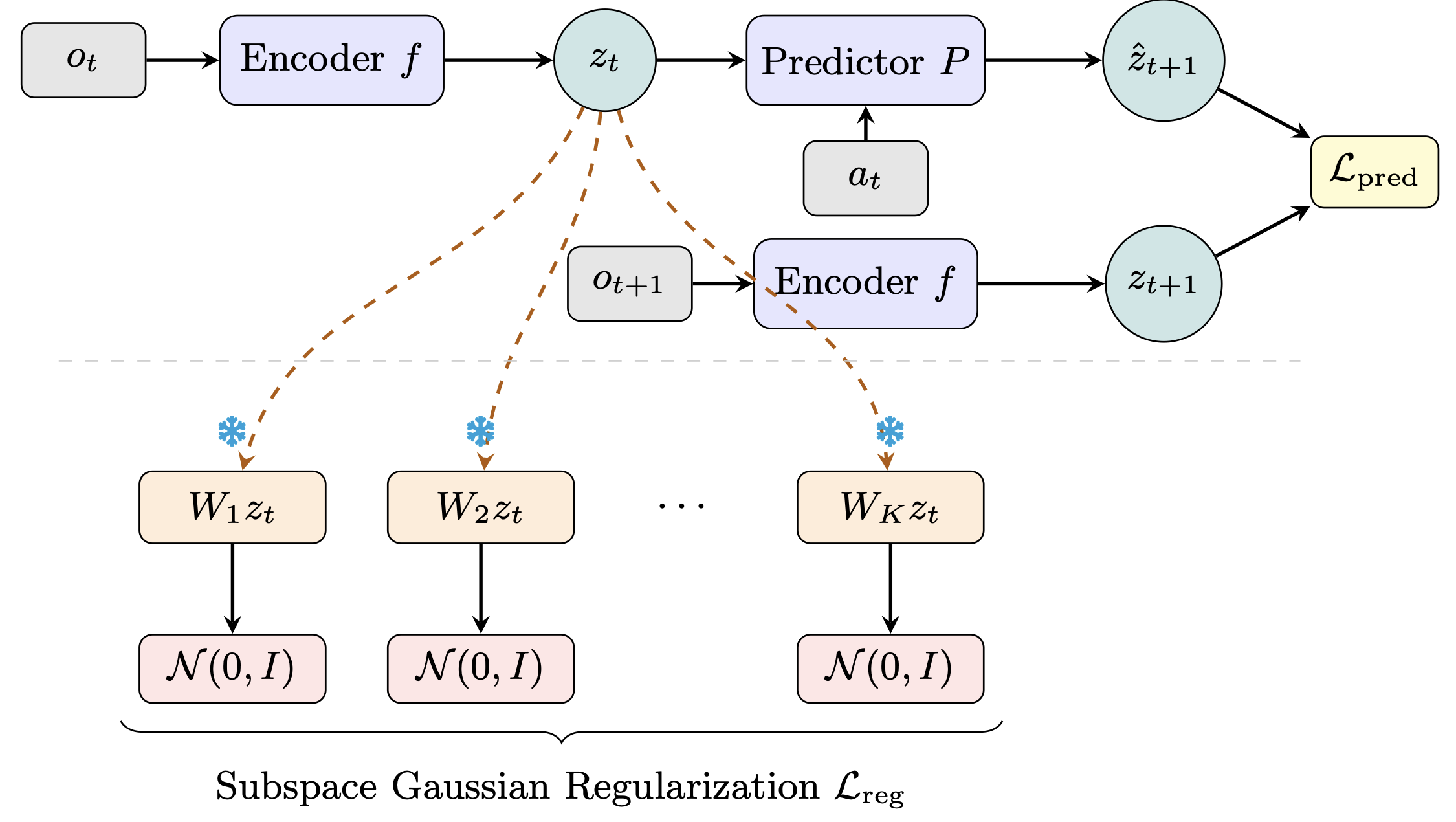
World models learn compact latent representations for planning without pixel reconstruction. LeWorldModel (LeWM), from LeCun's group at NYU, achieves stable end-to-end JEPA training by enforcing an isotropic Gaussian prior over the full latent space.
The flaw: real environment dynamics live on low-dimensional manifolds, so a global high-dimensional Gaussian is an overly rigid prior — mismatched to the task geometry. LeWM itself struggles most on low-intrinsic-dimension tasks like Two-Room.
Our fix (Sub-JEPA): apply the Gaussian regularization inside multiple frozen random orthogonal subspaces instead. This relaxes the global constraint while keeping the anti-collapse benefit. No new hyperparameters, same two-term objective.
Sub-JEPA consistently outperforms LeWM across all four benchmarks, with up to +10.7 pp on Two-Room. We also observe straighter latent trajectories and better physical state decodability as emergent benefits.

🌐 Project: https://kaizhao.net/sub-jepa
💻 Code: https://github.com/intcomp/sub-jepa
📄 Paper: https://arxiv.org/pdf/2605.09241
I'm currently working on a Mechanistic Interpretability project. The core goal is to understand how MLP and attention modules change after RLVR (Reinforcement Learning from Verifiable Rewards?).
To do this, I implemented a pipeline using Qwen 2.5-1.5B in three different versions:
I'm analyzing local MLP and attention activations using:
I'm curious to hear your feedback. What do you think about my project? Any suggestions, critiques, or ideas for further analysis? If you want to see my project : https://github.com/mirkzx04/Into-LLM-Reasoning
Thanks in advance!
{kind=link}
{kind=link}